Frame’s Architecture - A Streamlined Approach
At a high level, Frame consists of two main functional pieces that work together:
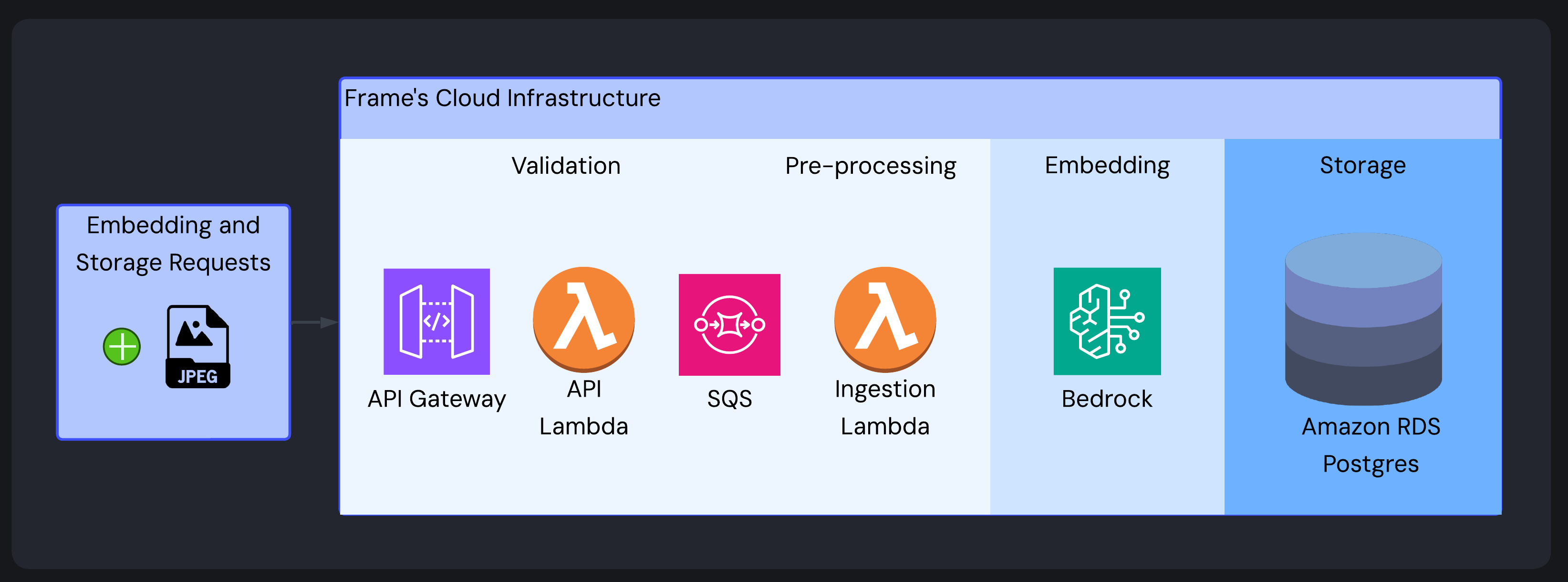
- Image Ingestion Pipeline: Processes image URLs and optional text descriptions into searchable vector embeddings. This includes image validation at the API level, asynchronous processing via a queue, image pre-processing, image embedding, and embedding storage.
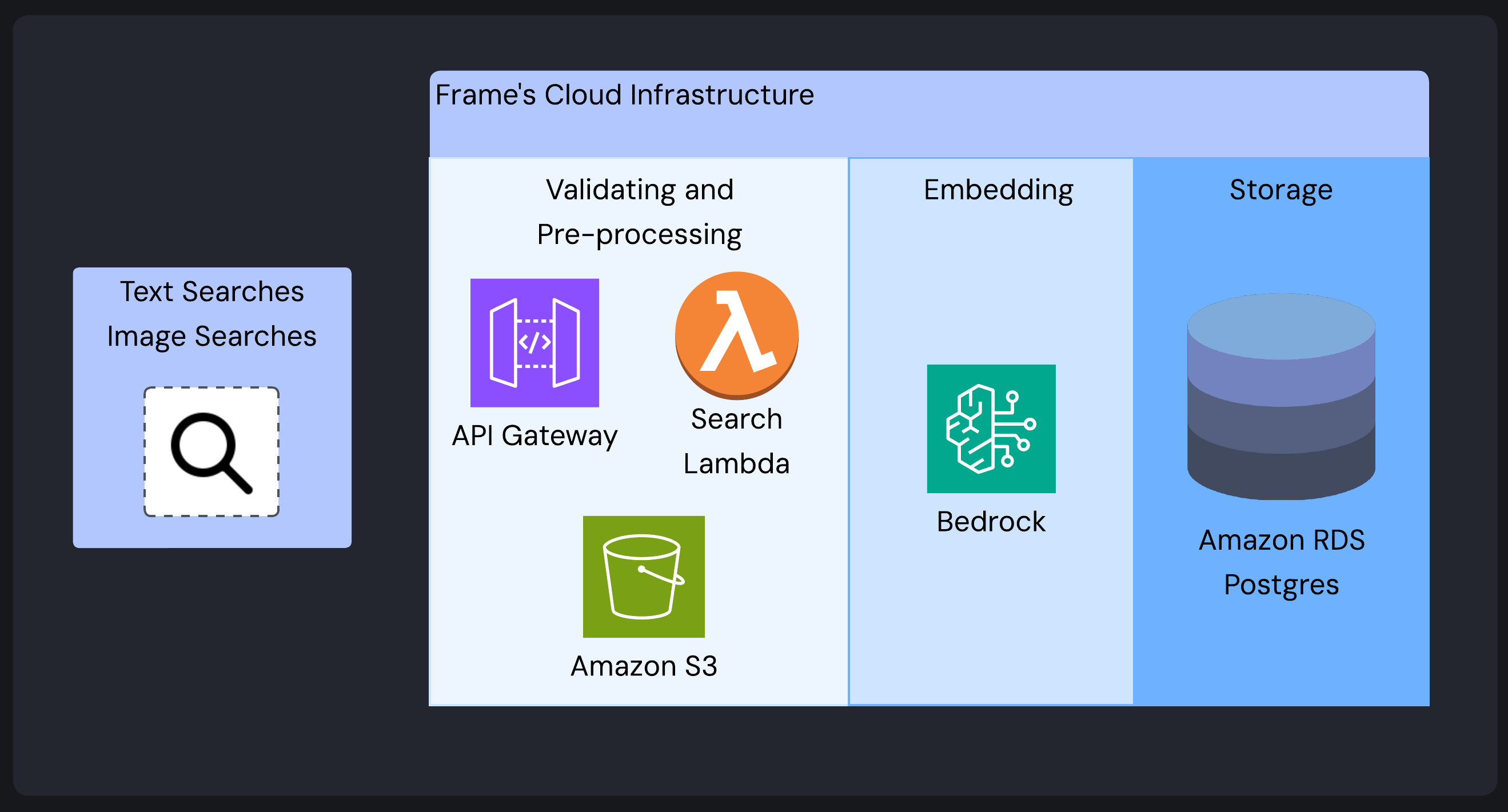
- Search System: Supports text, image URL, local image file uploads, and combination queries (text and image) by processing and embedding the query and using the query embedding to find similar items in the vector database.
Frame also supports image management operations like retrieval, deletion, and recommendations for similar images. Unlike search, recommendation functionality operates on images already embedded in the vector database. This means existing embeddings can be retrieved rather than generated anew, making recommendations particularly efficient.
The following sections discuss how Frame implements each essential function of an image embedding system: validating and processing, embedding, storage, and querying (search, recommendation, and other image management).
1. Validating and Pre-processing
When a user sends images to Frame’s ingestion endpoint via the SDK (demonstrated above), the request follows a carefully designed flow.
The request lifecycle starts at the AWS API Gateway. The API Gateway validates an API key and then proxies the request to a Lambda built with the web application framework Hono (hereafter referred to as the API Lambda). The API Lambda immediately validates the image format, size, and integrity.
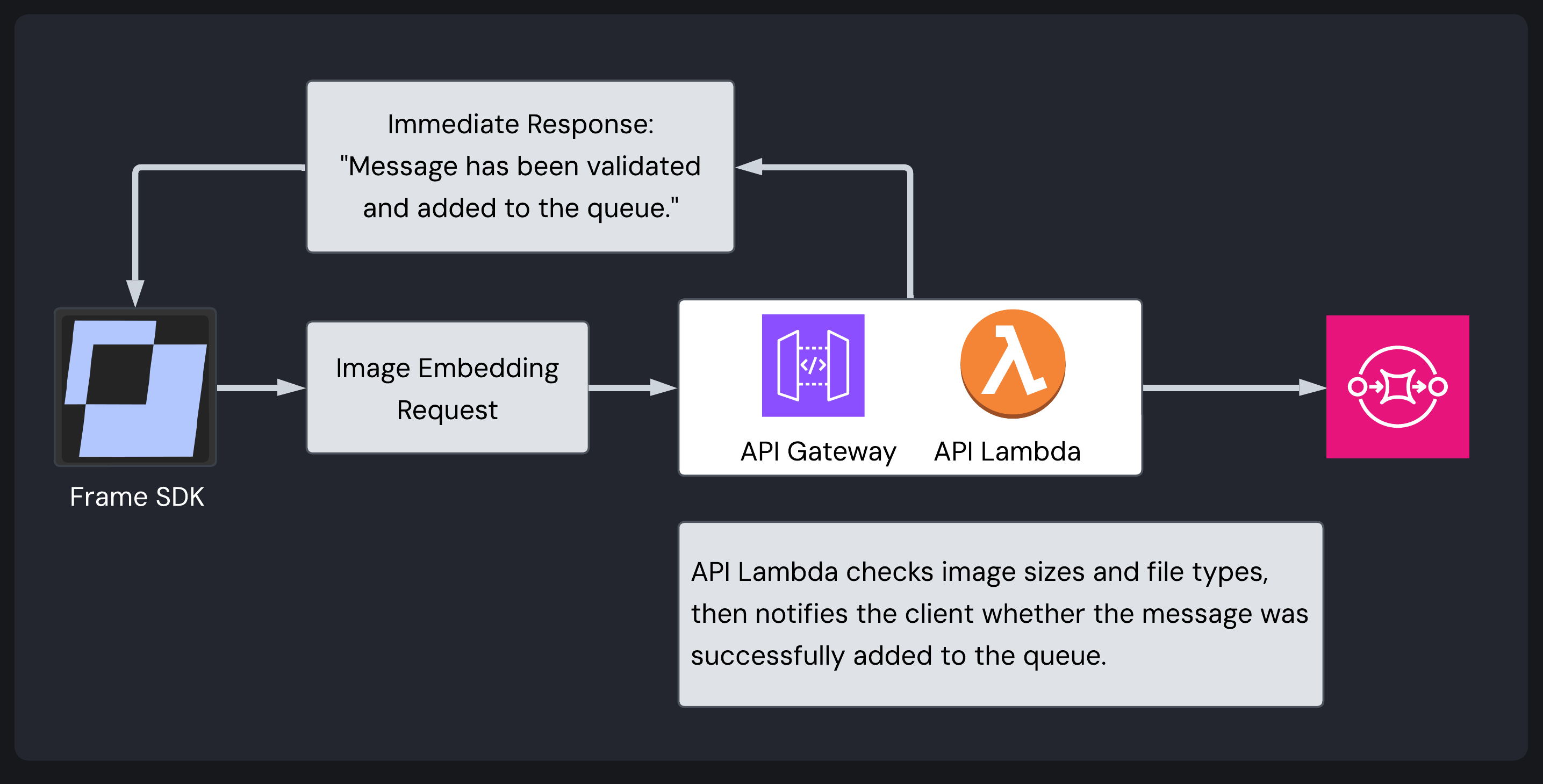
Rather than making users wait while large image files are processed asynchronously, the API Lambda sends validated image data to an AWS Simple Queue Service (SQS) queue. This allows the API Lambda to return an immediate response to the user. A queue decouples API request handling from intensive image processing while providing fault tolerance and automatic retries.
A second Lambda (the Image Ingestion Lambda) retrieves queue requests and processes them systematically via several critical transformations:
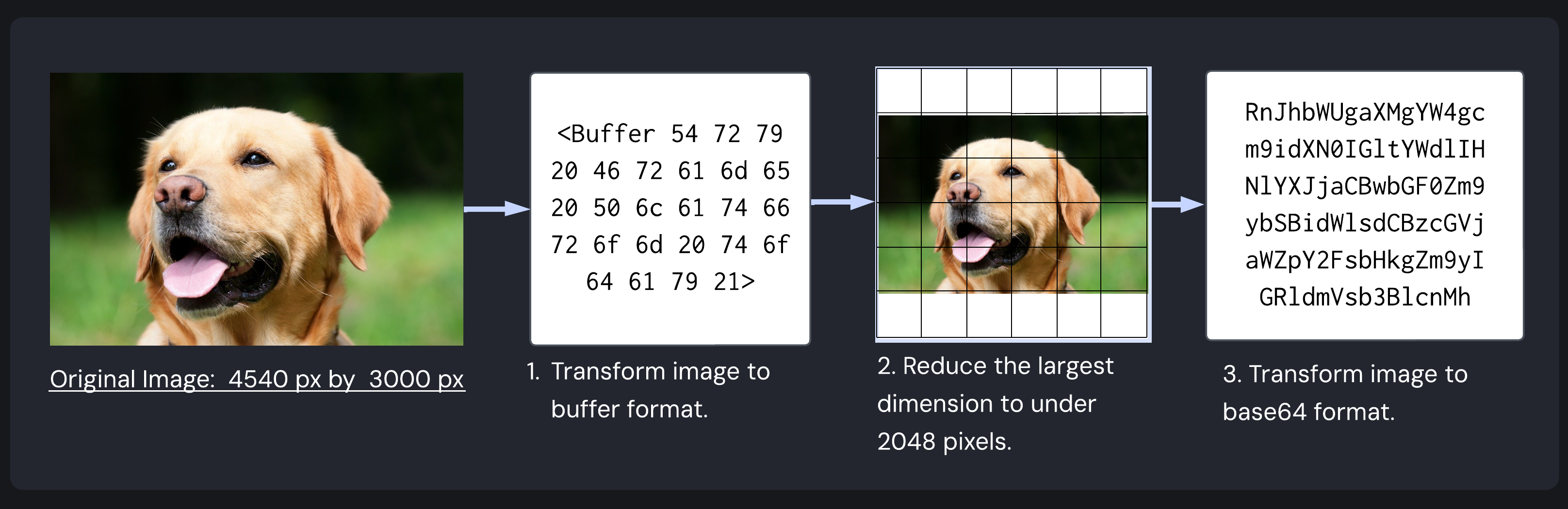
- Converting the input image to a binary buffer, which can be used by the sharp Node.js image processing library.1
- Using sharp to resize the image to standardized dimensions specified by the Titan embedding model (maximum 2048 pixels on any side).2
- Converting the processed image to a base64-encoded string for HTTP transmission to the embedding model’s API.
Users upload their images, and the system’s automated embedding pipeline handles all processing operations behind the scenes, eliminating wait times while ensuring optimal resource allocation.
2. Embedding
Pre-processed images are transformed into vector embeddings - the mathematical representation that enables similarity search - using Amazon Bedrock’s Titan Multimodal Embedding G1 model.
After pre-processing, the Image Ingestion Lambda converts the image to base64 and sends it to the embedding model, which returns a 1024-dimensional vector. This vector captures the image’s semantic characteristics for similarity search.
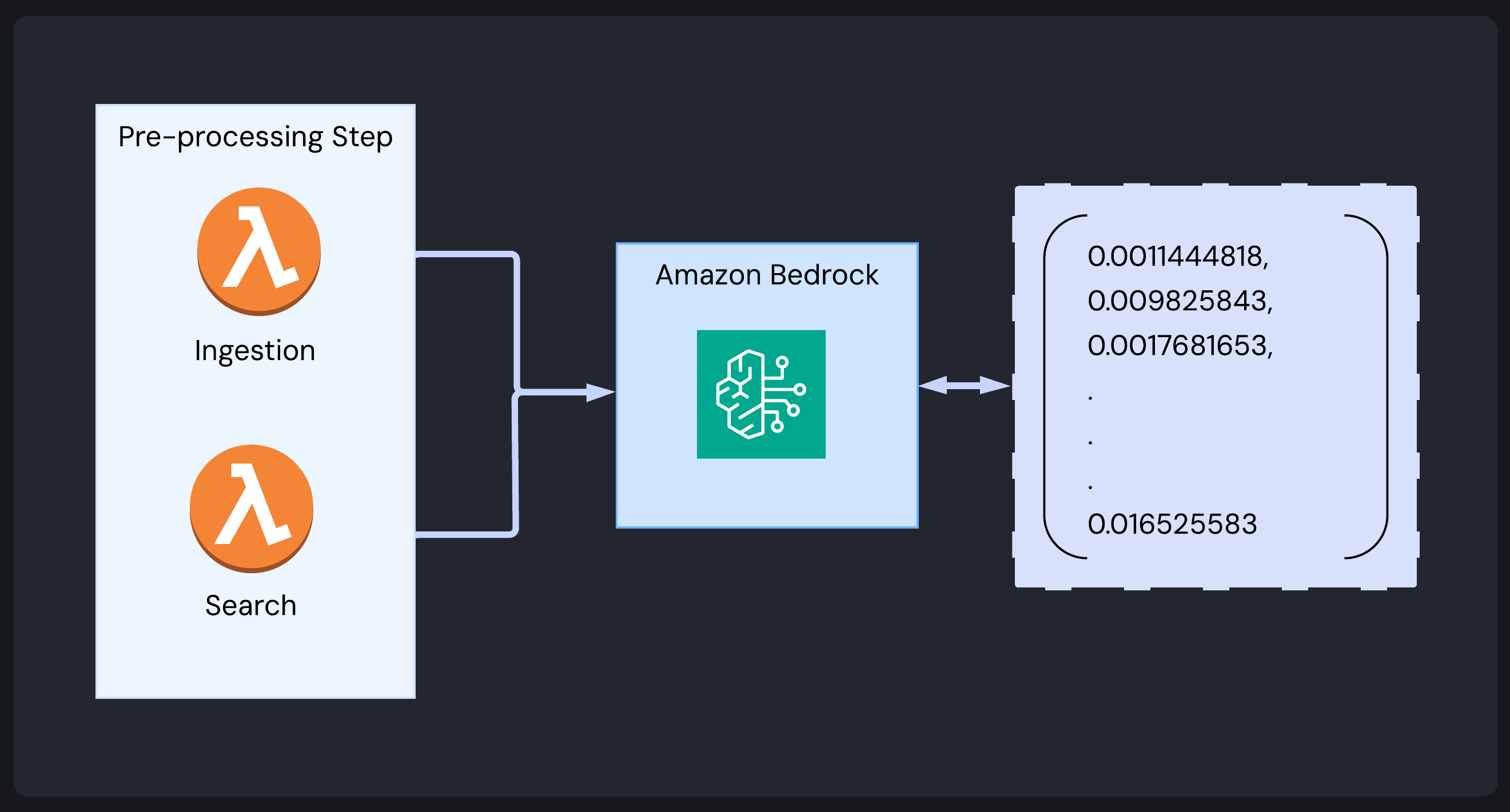
This same process occurs during search operations. However, a different Lambda (the Search Lambda) generates an embedding for the search query using the identical model and parameters.
Bedrock is part of the AWS ecosystem, simplifying deployment to users’ AWS accounts, removing dependencies on third-party APIs, and keeping operations within the user’s AWS account.
3. Storage
Frame uses PostgreSQL with the pgvector extension (deployed via Amazon RDS) to store and retrieve vector embeddings.
The Image Ingestion Lambda stores the vector embedding, along with an optional description and any associated metadata, in the vector database. Database credentials are secured via AWS Secrets Manager, ensuring sensitive information remains protected.
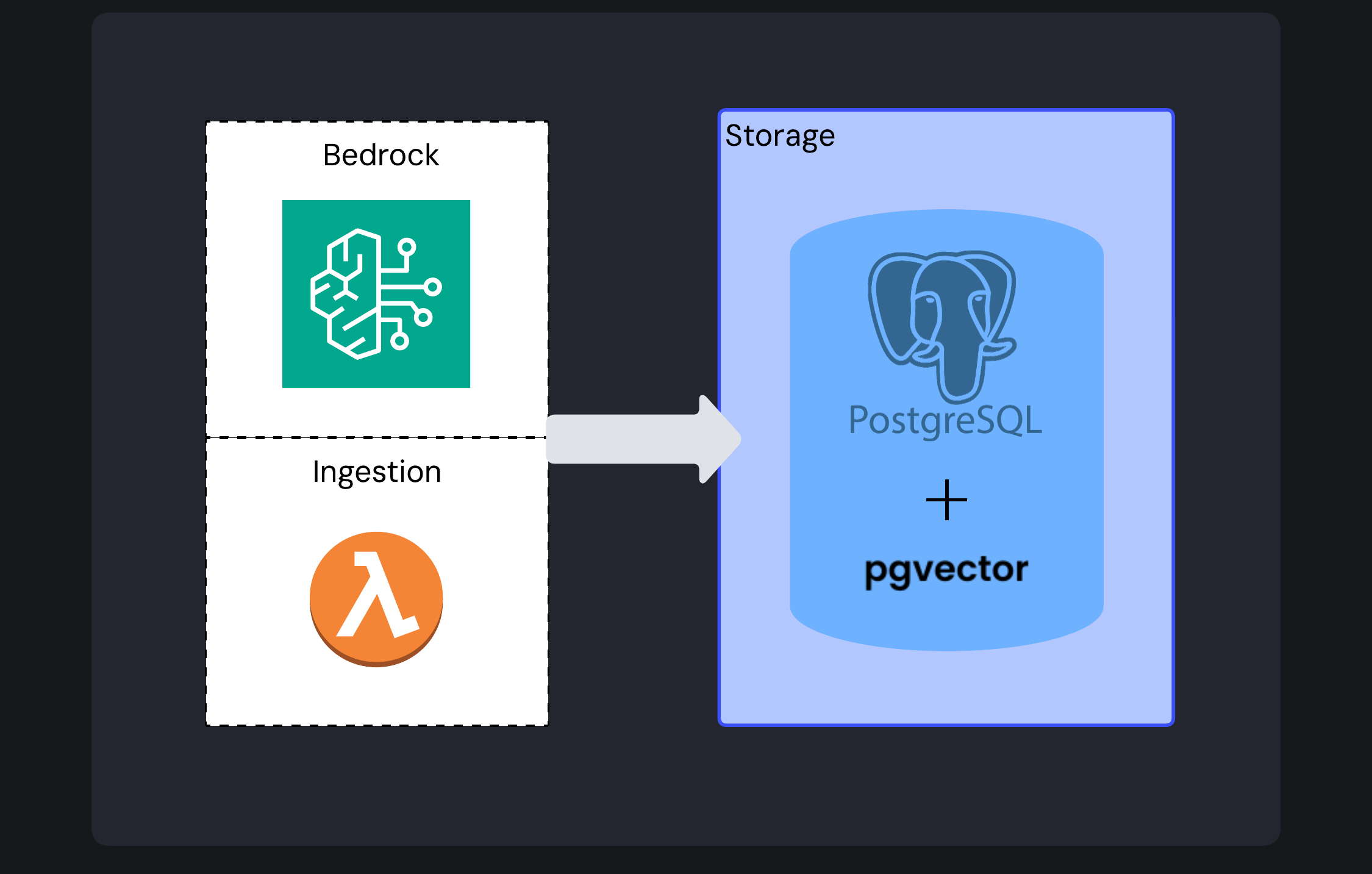
The choice of PostgreSQL with pgvector represents a deliberate tradeoff between performance and practical considerations. It gives us:
- AWS-native integration: Amazon RDS is fully managed within the AWS ecosystem and handles backups, scaling, and availability.
- Familiar technology: PostgreSQL is a proven database with a query language that most developers are familiar with.
- HNSW indexing: Dramatically speeds up similarity searches.
- Unified storage: Both vector data and metadata live in the same database.
For Frame users, PostgreSQL with pgvector delivers sufficient performance with substantially lower operational complexity than purpose-built vector databases.
4. Querying
Beyond ingestion and storage, Frame provides a set of powerful operations that allow users to interact with their stored embeddings. These operations fall into three main categories:
Search Operations
Frame supports multiple search modalities:
- Text queries: Natural language searches (“show me images of mountains”).
- Image URL queries: Finding similar images to one hosted online.
- Local image file uploads: Direct file upload for similarity search.
- Multimodal search: Combined image and text (“find images like this beach photo but at sunset”).
For text and image URL searches, the flow is straightforward - the API Lambda forwards requests to the Search Lambda, which generates a query embedding via Bedrock and queries the vector database for similar images using cosine similarity.
For local image file uploads, the API Lambda stores the file temporarily in an AWS S3 bucket. The S3 bucket allows access to the uploaded image via a URL. This URL is sent to the Search Lambda and processed like any other image URL search request. After the search is completed and the results are returned to the user, the image is deleted from the temporary S3 storage (thereby minimizing storage costs).
Users can configure search results by specifying the number of results they want (top N) and setting similarity thresholds to fine-tune relevance.
Recommendation Operations
The recommendation endpoint retrieves an existing embedding by ID, performs a similarity search against all stored images, and returns the top N most similar images (excluding the original).
This is particularly useful for “more like this” functionality in user interfaces, allowing for intuitive content exploration without requiring users to construct explicit queries.
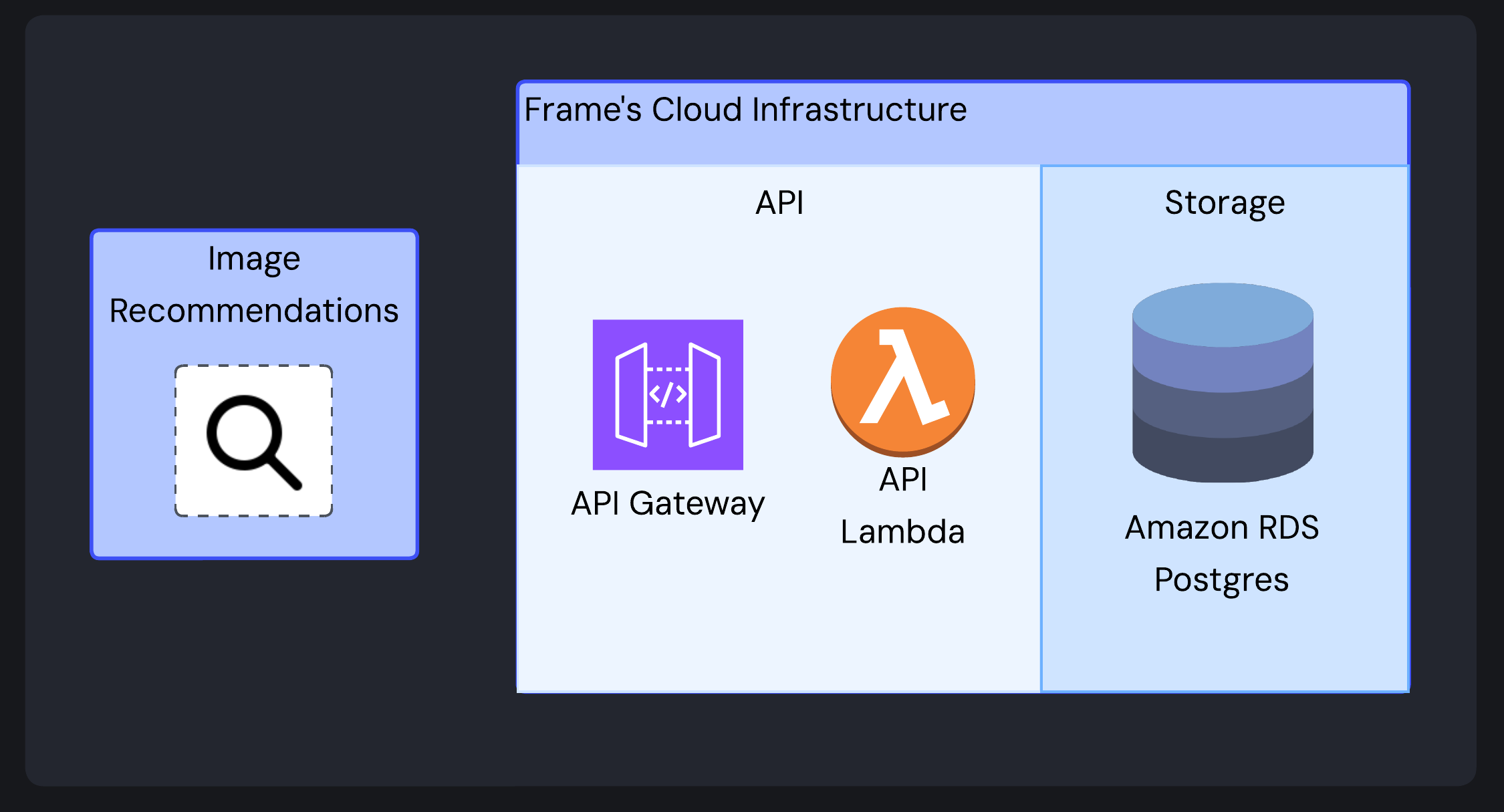
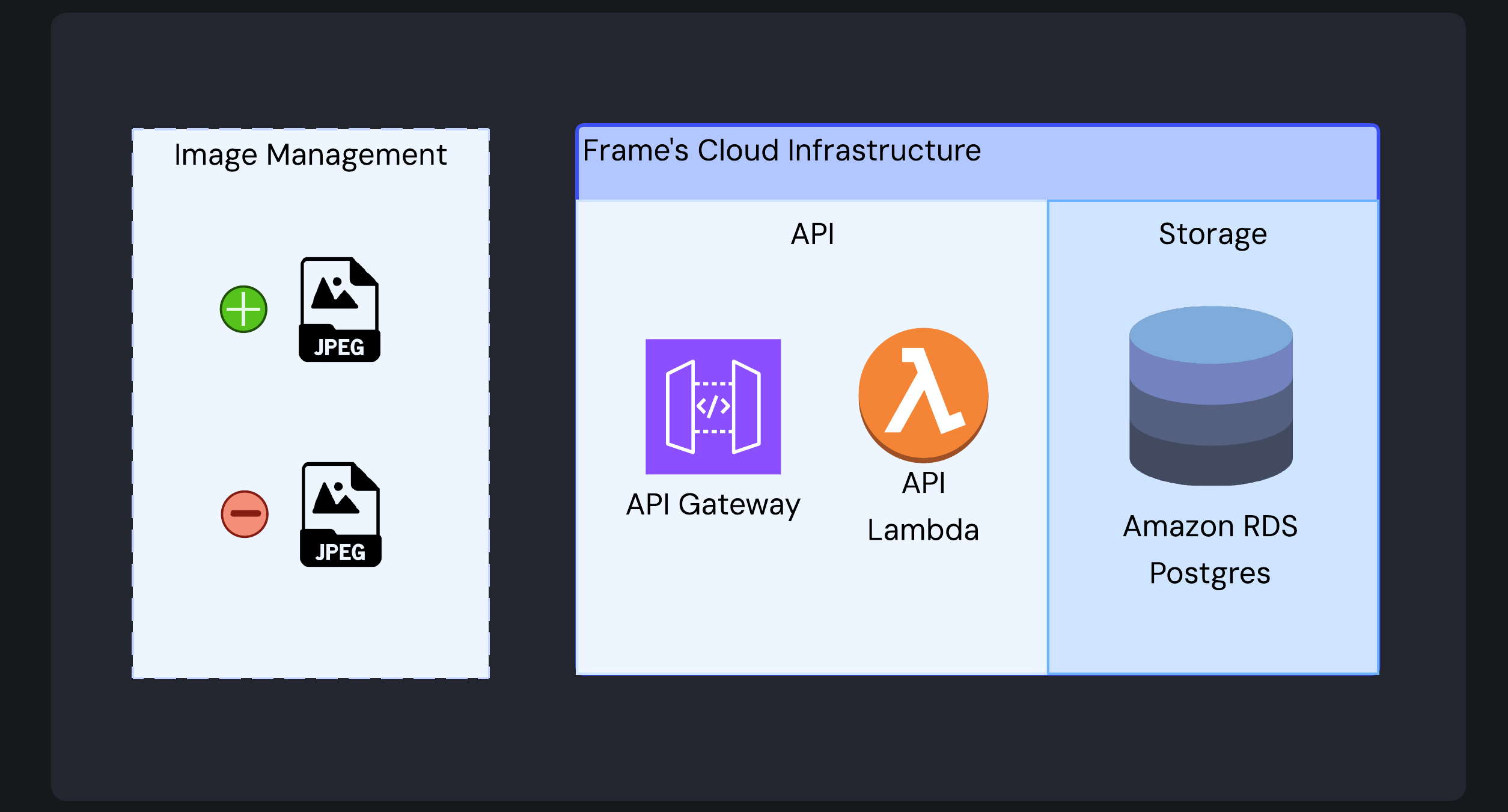
Image Management Operations
For basic image operations like listing, retrieving, or deleting images, the API Lambda connects directly to the database as these operations don’t require embedding generation or complex processing. This reduces complexity and improves response times.
Bringing It All Together with the SDK
A TypeScript-based SDK makes all of Frame’s functionality easily accessible to developers. The SDK exposes six core methods that map directly to Frame API endpoints.
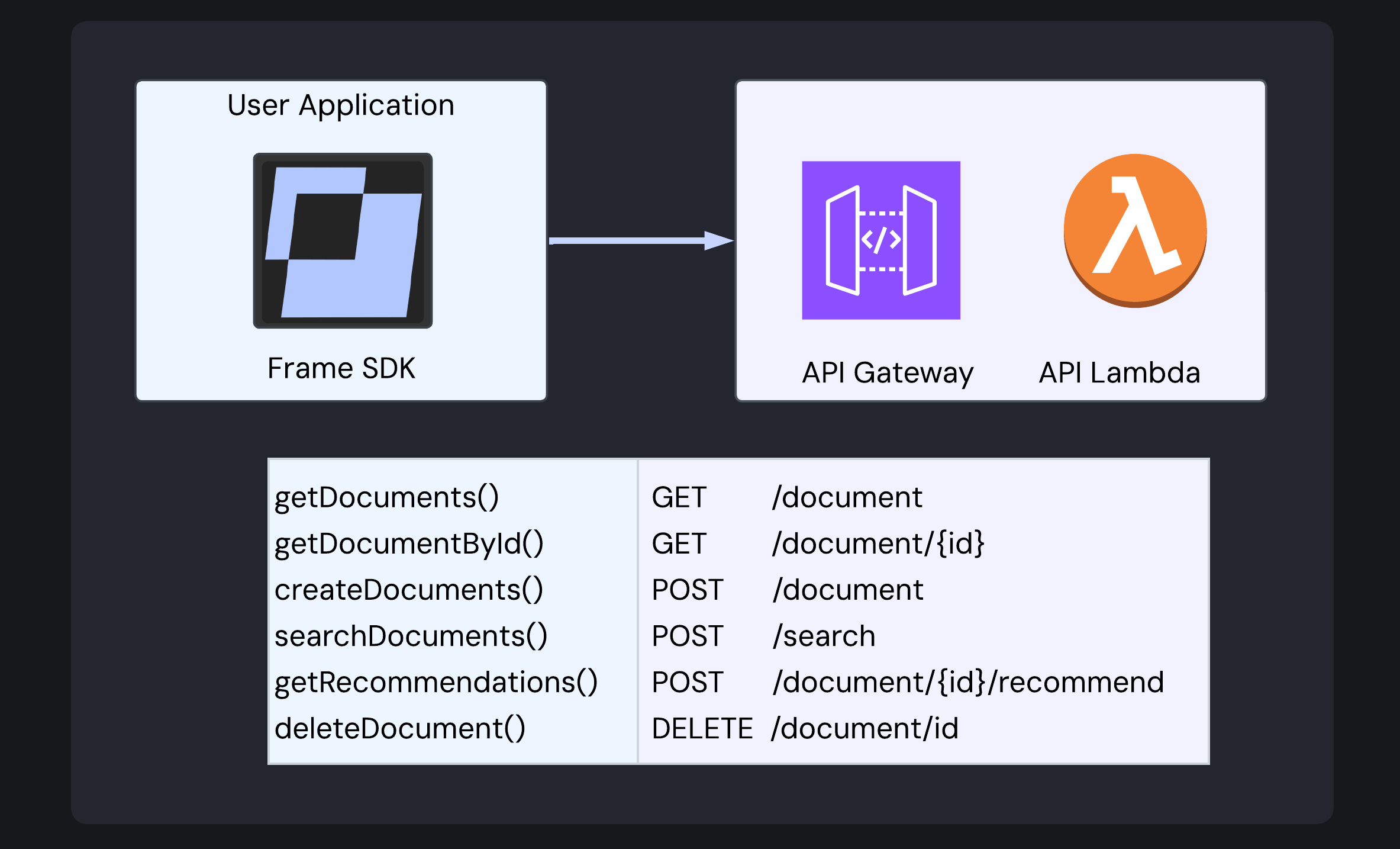
For detailed implementation guidance and examples, developers can refer to Frame’s comprehensive SDK documentation and demonstration videos.